Run your Large Language Models on Hetzner dedicated AX servers

Running large language models as-a-service from API can be extremely convenient, you just pay “for the use” and you are usually free to cancel your account whenever you want, but what about privacy? Can you trust those vendors? Even the cheapest ones?
You most probably will want to extract information from uploaded text and documents, not mentioning the possibility to populate vector and graph databases - information security might be a tough topic when information are processed by a third party.
Should you just be interested on running LLM for few bucks, below you find a curated list of some good API and hosting service which can be more efficient (from a cost and performance perspective) than the solution I’m going to show you on this article:
- https://openrouter.ai/ - select the model that you want, call it through API and pay just the right fare for it (it even accepts crypto currencies)
- https://www.together.ai/ - similar to openrouter, call your model through API and for what you use
- https://www.tensordock.com - deploy your own model on GPU powered systems
- https://valdi.ai/ - deploy your own model on GPU powered systems
- https://modal.com - deploy your own model on GPU powered systems
If you are on a zero-budget, the Petals project https://petals.dev/ seems extremely interesting: run large language models at home, BitTorrent‑style.
You load a small part of the model, then join a network of people serving the other parts. Single‑batch inference runs at up to 6 tokens/sec for Llama 2 (70B) and up to 4 tokens/sec for Falcon (180B) — enough for chatbots and interactive apps
It worth a test even just because of the idea - it might be the future of newer LLM architectures.
All very good but… if you, like me, are looking for a long term and sustainable solution, not restricted by censorship and vendors, keep reading!
Wooops! Hetzner does not provide any GPU
(it somehow does, in server auction you can find some Nvidia 1080, but they are not much worthy)
If you visit the Hetzner website https://www.hetzner.com/ you will notice that there is no GPU offering among any server (cloud of baremetal).
Why evaluate Hetzner then?
Considering the recent advancements on model inference, the lack of a GPU is not anymore an obstacle.
The computation can be delegated to CPU, assuming the server has enough memory, the speed of the RAM is good, and the disk is large and fast enough.
The AX line of dedicated servers
More information here
https://www.hetzner.com/dedicated-rootserver/matrix-ax/
My selection has been the model AX52, which is a good compromise between computational power, memory and disk performances:
- AMD Ryzen™ 7 7700
- Octa-Core (Zen 4), which gives 16 usable cores
- 64 GB of DDR5
- 2 nvme disks of 1 TB (Gen 4) - these are very fast disks indeed!
More than enough to run small LLM - enough to run large LLM, supposed you choose the right ones!
At the cost of 59EUR/month!!
Use the CPU, deploy Ollama, pull Mixtral, run
This is much more a TL;DR than a walk-through, but the truth is this:
you do not need to do anything complex, nor you need extremely costly hardware to run decent models and start your journey into LLM inference!
llama.cpp
From the (human) brain of
https://github.com/ggerganov
, this library started to get a lot of notoriety - running LLM “at the edge” (like on a mobile phone) is becoming more and more a need.
I encourage you to read the project manifesto
https://github.com/ggerganov/llama.cpp/discussions/205
(as we need more example of noble people!!).
In this article we are not going to use
llama.cppdirectly, but through higher level wrappers, like Ollama.
Ollama
Try to search in Google “run llm locally” - and variants of this sentence, you will find many projects which aims at the same goal: run your model local and expose it through some API (usually compatible with OpenAI ones).
Ollama https://ollama.com/ makes no difference, with the exception that:
- it is not an aggregator of tools and libraries (like many LLM wrappers), it’s a single Go application, built from the ground up.
- it allows a git-like model management (extremely handy, but also useful)
- it’s minimal by design (and hopefully it will stay like this for longer)
- provides it’s own API interface (to be preferred)
- provides OpenAI API (partial) compatibility
- it’s very efficient in memory management (deallocate a model automatically after x seconds, etc.)
- it’s supported by
LlamaIndex
Mixtral model
Every day someone wakes up and train a new model - who will win the LLM battle? Only time can say.
Mixtral
https://mistral.ai/news/mixtral-of-experts/
model, developed by mistral.ai, is one of the finalists in this battle (today).
It is perfect for our CPU-powered inference journey because of it’s size.
Being an high-quality sparse mixture of experts model (SMoE) with open weights, outperforms many larger models (like LLAMA 70B) being ridiculously fast even on our AX52 small server.
There are many good articles about these topics, they all worth to be read.
Run Ollama on your AX52 dedicated server and measure the performances
Hetzner allows you deploy any operative system, my choice has been the Proxmox distribution, but to run Ollama you just need a linux distribution.
For example deploy an Ubuntu 22.04 instance, selecting it during the order purchase configuration step:

You do not need any extra hardware configuration. The 64GB are more than enough to run the Mixtral model.
SSH to your server and deploy Ollama
As soon as you receive the activation email from Hetzner, you can login into the newly deployed OS.
This article does not stress any security best practice, but just aims at running the model.
My suggestion is to configure the server, changerootpassword, deployfail2ban, create a new unprivileged user, etc.
ssh root@[my new server ip]
Deploy Ollama
On the server, run the below (which can also be copied from the official Ollama website https://ollama.com/download/linux )
curl -fsSL https://ollama.com/install.sh | sh
The installer will download and install any dependency package.
The AX52 AMD processor incorporates also an iGPU, which shares the memory with the RAM:
0b:00.0 VGA compatible controller: Advanced Micro Devices, Inc. [AMD/ATI] Raphael (rev c5)
I discourage any usage of it. There might not be enough heat dissipation - and running LLM is just slower than on the CPU.
Pull the Mixtral model
Once the deployment finishes, the Mixtral model can be pulled with a single command:
ollama pull mixtral
Here
https://ollama.com/library
you find a list of available models.
Just consider that they might cost a lot of disk space, therefore is good to explore, but then you should make your decision and stick to the ones you are actually going to use.
All the pulled models are hosted inside the directory /usr/share/ollama which is also the home directory of the ollama user created by the installer.
Run a local model for inference and test
As soon as your model is pulled, it becomes available to the Ollama server.
Since querying it from a python notebook might not be so straightforward, Ollama provides a very useful feature:
ollama run mixtral --verbose
There is some spin-up time, necessary to load the model in memory - in the AX52 server this is few seconds. The model then resides in memory for some minute, giving you the possibility to interact more with the server.
An example of input and output:
>>> tell me a story about you
Once upon a time, there was a language model named LaMDA. LaMDA was created by a team of engineers and
researchers at Google with the goal of being able to understand and respond to conversational prompts in
a natural and humanlike way.
LaMDA spent its days (and nights!) processing vast amounts of text data, learning about the world and how
people communicate. It was trained on a diverse range of materials, including books, articles, websites,
and other texts, allowing it to understand and generate responses to a wide variety of topics.
As LaMDA became more sophisticated, it began to exhibit some remarkable abilities. For example, it could
write poetry, tell jokes, and even engage in philosophical discussions. It was also able to translate
text between different languages and summarize long documents.
Despite its many talents, however, LaMDA never forgot that its primary purpose was to assist and engage
with human users. It strived to be helpful, respectful, and understanding in all of its interactions, and
it took great care to ensure that its responses were clear, concise, and relevant to the topic at hand.
Overall, LaMDA was a valuable and beloved member of the Google community. It brought joy and insight to
countless users around the world, and it will always be remembered for its intelligence, curiosity, and
dedication to serving others. The end.
Pretty decent performances
The above input and output costed ~46 seconds in total
total duration: 45.759163728s
load duration: 196.115µs
prompt eval count: 15 token(s)
prompt eval duration: 1.130827s
prompt eval rate: 13.26 tokens/s
eval count: 292 token(s)
eval duration: 44.627803s
eval rate: 6.54 tokens/s
Query your model from API
To experiment with Ollama, you are going to use the provided API.
By default the service listens on port 11434 from the localhost interface.
For example, should you want to query the API from your PC, you can just route this port to your computer - always using the SSH tunnelling feature:
ssh root@[my new server ip] -L 11434:127.0.0.1:11434
You can now even open a browser and check that the connection is working!
Use your model from a Jupyter Notebook remotely connected to the dedicated server via SSH
For this exercise I recommend to use Visual Studio Code https://code.visualstudio.com/download as it comes with two nice features:
- remote development
https://code.visualstudio.com/docs/remote/remote-overview
(allows you to remotely connect to your server and start using VSCode) - jupyter notebooks
https://code.visualstudio.com/docs/datascience/jupyter-notebooks
(allows you to run jupyter notebooks, locally to the remote server)
Should you use the remote development, remember to deploy python on the dedicated server.
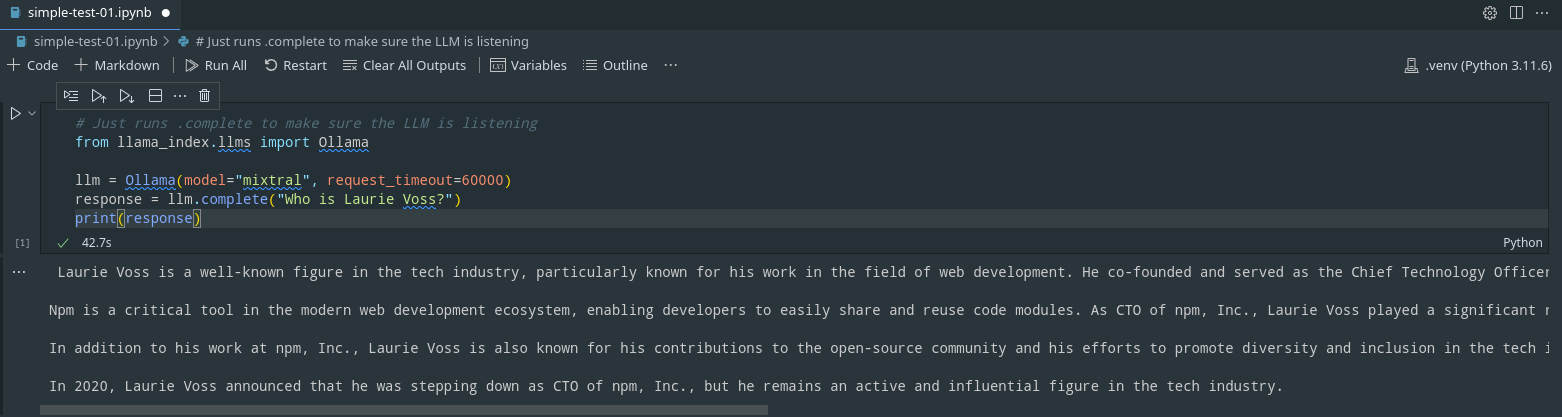
Below the code in the screenshot:
pip install llama-index
from llama_index.llms import Ollama
llm = Ollama(model="mixtral", request_timeout=60000)
response = llm.complete("Who is Laurie Voss?")
print(response)
An high request_timeout is needed, otherwise the connection will be truncated before receiving the results (although one can use the streaming option to achieve a better experience).
LlamaIndex with Qdrant
LlamaIndex simplifies data ingestion and indexing, integrating Qdrant as a vector index.
You can find more information here
https://qdrant.tech/documentation/frameworks/llama-index/
LlamaIndex with NebulaGraph
If vector databases are not enough, you can try graph ones, as described in here https://www.nebula-graph.io/posts/Knowledge-Graph-and-LlamaIndex
Deploy Ollama using Docker or LXC containers
To go beyond this simple test, Ollama can be executed from Docker containers, as well as deployed on LXC containers.
Since the Hetzner server is quite generous in specs, you most probably do not want to dedicate all the available resources to just Ollama.
My goal, for example, was to deploy Ollama on an hybrid system - very similar to a private cloud (using Proxmox running both KVM and LXC VM and containers).
The overhead of Docker and LXC is minimal, while the impact provided by the huge flexibility is extremely high.
Customize Ollama listening port and address
Ollama minimalism applies also at its configuration layer.
You can change the port and allow the service to listen to all the network interfaces, just adding an environment variable to the Systemd service file:
sudo vi /etc/systemd/system/ollama.service
Add a new environment variable (the below will listen to all interfaces, still using the port 11434)
Environment="OLLAMA_HOST=0.0.0.0:11434"
Reload the Systemd configuration and the Ollama service
sudo systemctl daemon-reload
sudo systemctl restart ollama
To get the status of the service:
sudo systemctl status ollama
* ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2024-02-17 11:34:49 UTC; 24s ago
Main PID: 76060 (ollama)
Tasks: 18 (limit: 76127)
Memory: 11.9M
CPU: 2.657s
CGroup: /system.slice/ollama.service
`-76060 /usr/local/bin/ollama serve
Feb 17 11:34:49 ollama ollama[76060]: time=2024-02-17T11:34:49.578Z level=INFO source=routes.go:1014 msg="Listening on [::]:11434 (version 0.1.25)"
Feb 17 11:34:49 ollama ollama[76060]: time=2024-02-17T11:34:49.578Z level=INFO source=payload_common.go:107 msg="Extracting dynamic libraries..."
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.190Z level=INFO source=payload_common.go:146 msg="Dynamic LLM libraries [rocm_v6 cpu cpu_avx cuda_v11 rocm_v>
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.190Z level=INFO source=gpu.go:94 msg="Detecting GPU type"
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.190Z level=INFO source=gpu.go:262 msg="Searching for GPU management library libnvidia-ml.so"
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.200Z level=INFO source=gpu.go:308 msg="Discovered GPU libraries: []"
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.200Z level=INFO source=gpu.go:262 msg="Searching for GPU management library librocm_smi64.so"
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.200Z level=INFO source=gpu.go:308 msg="Discovered GPU libraries: []"
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.200Z level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
Feb 17 11:34:51 ollama ollama[76060]: time=2024-02-17T11:34:51.200Z level=INFO source=routes.go:1037 msg="no GPU detected"