Multi-cloud load-balance and failover with HAProxy
Before jumping into a full reading, please focus on the below sentence:
Your services
needdeserve a proper failoverinstancechance
If you think the contrary, you can skip reading the article, the internet is plenty of better ways to waste your time!
Cloud and services high availability
From costs perspective, the moment you jump into the high availability topic when relying a cloud vendor (i.e. Azure or AWS), things are getting serious.
I’m not a cloud engineer, although the thumb rules applies: you are going to at least double the infrastructure and its costs, with very little chances to spare some buck for Xmas presents.
Disclaimer: Cloud HA solutions are often more reliable, also because are less complex to setup
If you can afford it, go for it.
This article does not want to compete with any cloud philosophy and it is obvious that any hybrid solution will require much more human intervention than few clicks on a web page, therefore the risk of a wrongly configured balancing infrastructure is inherently higher than a boxed solution.
Could a multi-cloud solution be good as well?
With the inflation reaching the stars, you might want to look for out-of-the-box solutions.
Let’s consider a couple of assertions:
- High Availability is usually a multi-zone deployment of the same service/stack, an other cloud vendor might fit as well
- The failover instance could be re-purposed to serve some specific workload (i.e. staging or development)
- The two (or more, there is no limit) instances could be differently shaped, assuming we accept a loss in performances during a failover event
The scenario I’m going to cover is the below:
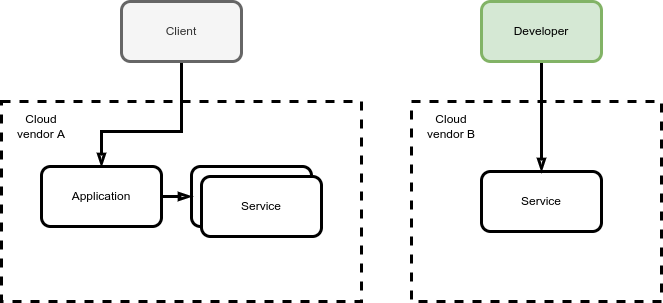
We have a production deployment (on cloud-vendor-A) which consists of:
- an application
- a service
Both the service and the application could be anything, for simplicity we could think of them as pods running on K8s clusters.
On cloud-B we deployed the same service but without any application - although nobody prohibit us from deploying it here too.
Cloud-B instances might have less nodes, therefore be cheaper and shaped to a specific workload (in the example development purposes).
Would a multi-zones configured cluster work as well?
Depending on the technology you are using, it could. For example K8s allows it https://kubernetes.io/docs/setup/best-practices/multiple-zones/ while Docker Swarm does not (I have quite some experience with Swarm and it’s unreliable when deployed on a multi-zone topology).
Relying entirely on the networking capabilities of your container/orchestration solution might fit in some scenario, although when things get serious (and complex), it is my opinion to remove all the “magic” from the below and start collecting metrics. With K8s this is way too much complex to match the costs/effort.
Move the balancer near the application
This could be also the TL;DR, as the simple solution I’m pushing is: move the balancer or reverse proxy near the product, and configure it to route the request to the appropriate backend.
HAProxy
According to HAProxy http://www.haproxy.org/ website tagline, we can say that HAProxy is:
The Reliable, High Performance TCP/HTTP Load Balancer
Maybe it’s not all true but with just few configuration lines we can spin-up a reverse proxy able to:
- route the request to the appropriate backend
- persist the connection to the appropriate backend (even when the situation is recovered)
- balance the requests through several backends, also when on a failover state
- monitor the status of the backends, even with complex queries (i.e. HTTP checks)
Experiment with HAProxy and Docker
Before jumping into any action, it’s better to setup a playground environment to:
- starts three echo services (they just shows HTTP server variables, useful to understand any injected HTTP headers at service level)
- starts one HAProxy with two backup nodes and persistency setup
The docker-compose.yml file looks like the below:
version: '3.9'
services:
echo1:
image: jmalloc/echo-server:latest
echo2:
image: jmalloc/echo-server:latest
echo3:
image: jmalloc/echo-server:latest
haproxy:
image: haproxytech/haproxy-alpine:2.4
container_name: haproxy
restart: always
ports:
- "3000:3000"
- "8404:8404"
volumes:
- ./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg
The whole routing logic resides on the haproxy.cfg file:
global
stats socket /var/run/api.sock user haproxy group haproxy mode 660 level admin expose-fd listeners
log stdout format raw local0 info
defaults
mode http
timeout client 10s
timeout connect 5s
timeout server 10s
timeout http-request 10s
log global
frontend stats
bind *:8404
stats enable
stats uri /
stats refresh 10s
frontend myfrontend
bind :3000
default_backend webservers
backend webservers
option allbackups
cookie SERVERID insert indirect nocache
server s1 echo1:8080 check cookie s1
server s2 echo2:8080 check cookie s2 backup
server s3 echo3:8080 check cookie s3 backup
A failover condition can be easily created turning off the s1 server:
docker ps
docker stop [id of the container]
Useful configuration entries
option allbackups
Used to cycle all the available backup nodes; on a failover event allows performances matching or better resources usecookie SERVERID insert indirect nocache
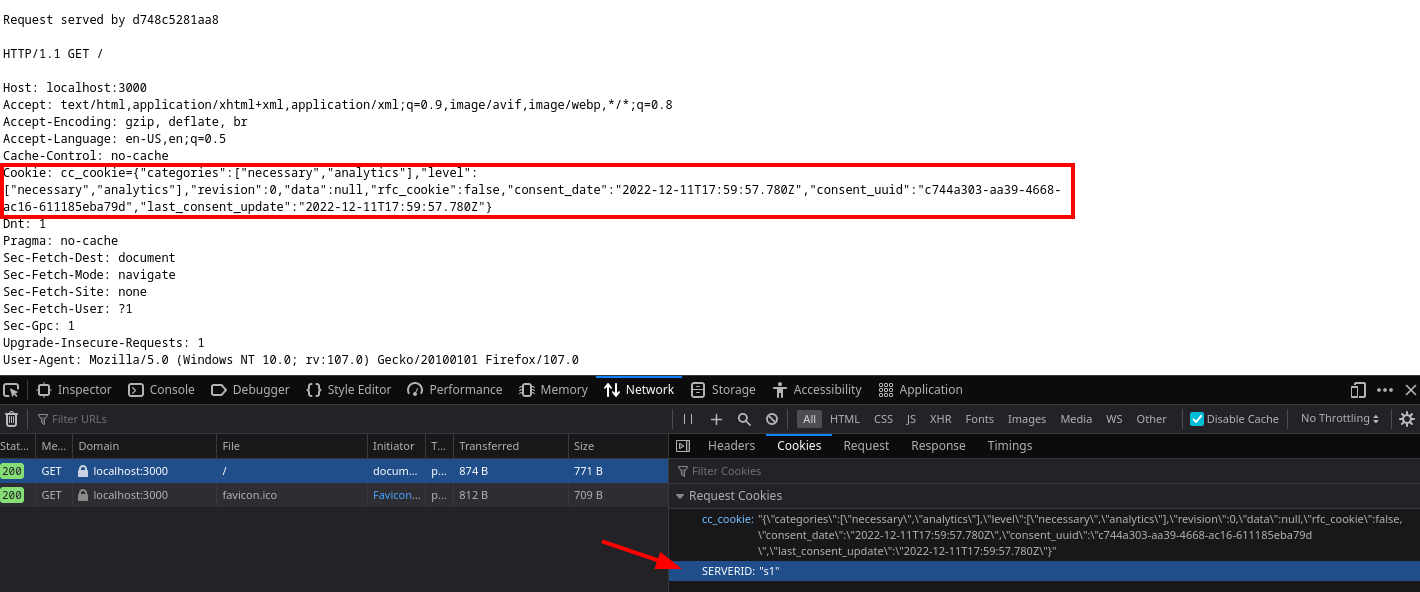
This option inject a cookie namedSERVERIDinto any request. This is extremely useful in case the services balanced are not stateless.
Suppose you are balancing over a remote datacenter, the DB is therefore not replicated but you have to serve multiple requests. The moment the connectivity withs1is restored, you will want to keep the client routed to the appropriate backend server.
HAProxy has several options for persistency, this one is transparent (i.e. the service is unaware of any session, but uses, for example, a local storage to persist some intermediate elaboration).
With the stack running, a simple F12 on your browser at the URL http://localhost:3000 will highlight that HAProxy injected a cookie to your browser, but the cookie is not pushed back to the echo server:
Monitoring dashboard as a bonus
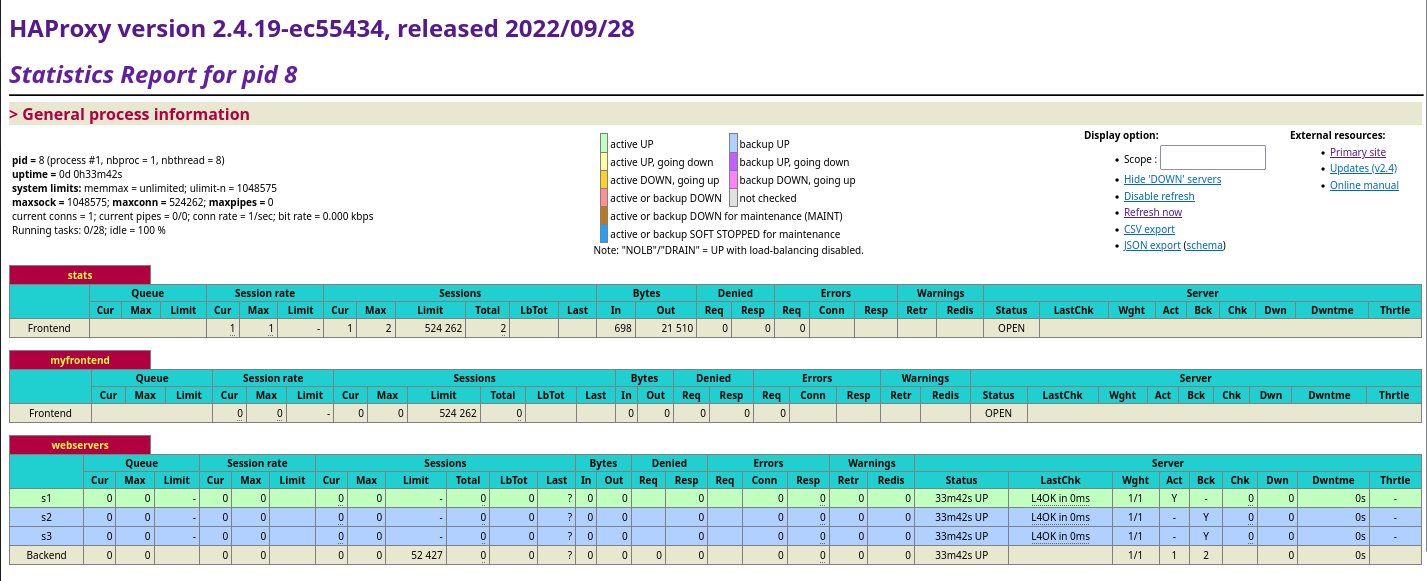
HAProxy can provide an off-the-shelf monitoring dashboard, very handy when experimenting with the configuration, a lifesaver when troubleshooting a connection issue.
There is the possibility to consume Prometheus metrics? Why bother?
https://www.haproxy.com/blog/haproxy-exposes-a-prometheus-metrics-endpoint/
that’s because I’m lazy and I like the old fashioned look and feel of this dashboard!
An example use case: a memory and CPU eager process run on the cheapest Cloud-B provider
Cloud can be quite pricey the very moment you have to turn on services which uses a lot of memory and CPU (e.g. solve linear optimization problems).
A solution could be to use the cheaper could provider for this scope and turn on only a minimal failover environment near the application (eventually to scale up if and when needed, supposed the situation does not recover quickly enough).
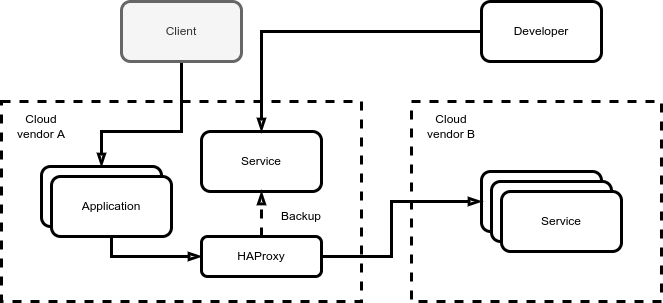
The HAProxy container can actually run within the application cluster, giving much more reliability and stability to the whole system.
The so-called backup/failover instance is kept up and running but used for development and staging use only.
Since the service is supposed to be served through the HTTP protocol, the overhead of a VPN tunnel is not needed.
The service can implement an authentication/authorization layer, avoiding accessory costs like cloud-to-cloud or cloud-to-prem VPN gateways (which are billed and they too would require redundancy in case of an HA configuration).
Why not Nginx?
This is a question I did to myself the very moment I dragged the reverse proxy near the application.
Nginx is usually considered a lightweight solution, therefore is the first choice when there is a container scenario.
Unfortunately not all the cool features used in this scenario are available, for example you need Nginx Pro to:
- perform complex HTTP health checks
- configure a reliable persistency rule based (i.e. not just based on the source IP address)
The memory footprint of HAProxy is not so terrible ~ 500MB and up to a couple of GB under heavy use (bigger than Nginx). Would be interesting to play a bit more with the configuration and come up with a better optimized runtime - nowadays, and to my specific case, memory is not an issue (as we can afford some hundred of MB more).
Some good reads
- Failover and Worst Case Management with HAProxy
https://www.haproxy.com/blog/failover-and-worst-case-management-with-haproxy/ - Load Balancing, Affinity, Persistence, Sticky Sessions: What You Need to Know
https://www.haproxy.com/blog/load-balancing-affinity-persistence-sticky-sessions-what-you-need-to-know/